


Artificial Intelligence, Data Science and E-health in Vision Research and Clinical Activity
More infoOptical coherence tomography (OCT) has revolutionized ophthalmic clinical practice and research, as a result of the high-resolution images that the method is able to capture in a fast, non-invasive manner. Although clinicians can interpret OCT images qualitatively, the ability to quantitatively and automatically analyse these images represents a key goal for eye care by providing clinicians with immediate and relevant metrics to inform best clinical practice. The range of applications and methods to analyse OCT images is rich and rapidly expanding. With the advent of deep learning methods, the field has experienced significant progress with state-of-the-art-performance for several OCT image analysis tasks. Generative adversarial networks (GANs) represent a subfield of deep learning that allows for a range of novel applications not possible in most other deep learning methods, with the potential to provide more accurate and robust analyses. In this review, the progress in this field and clinical impact are reviewed and the potential future development of applications of GANs to OCT image processing are discussed.
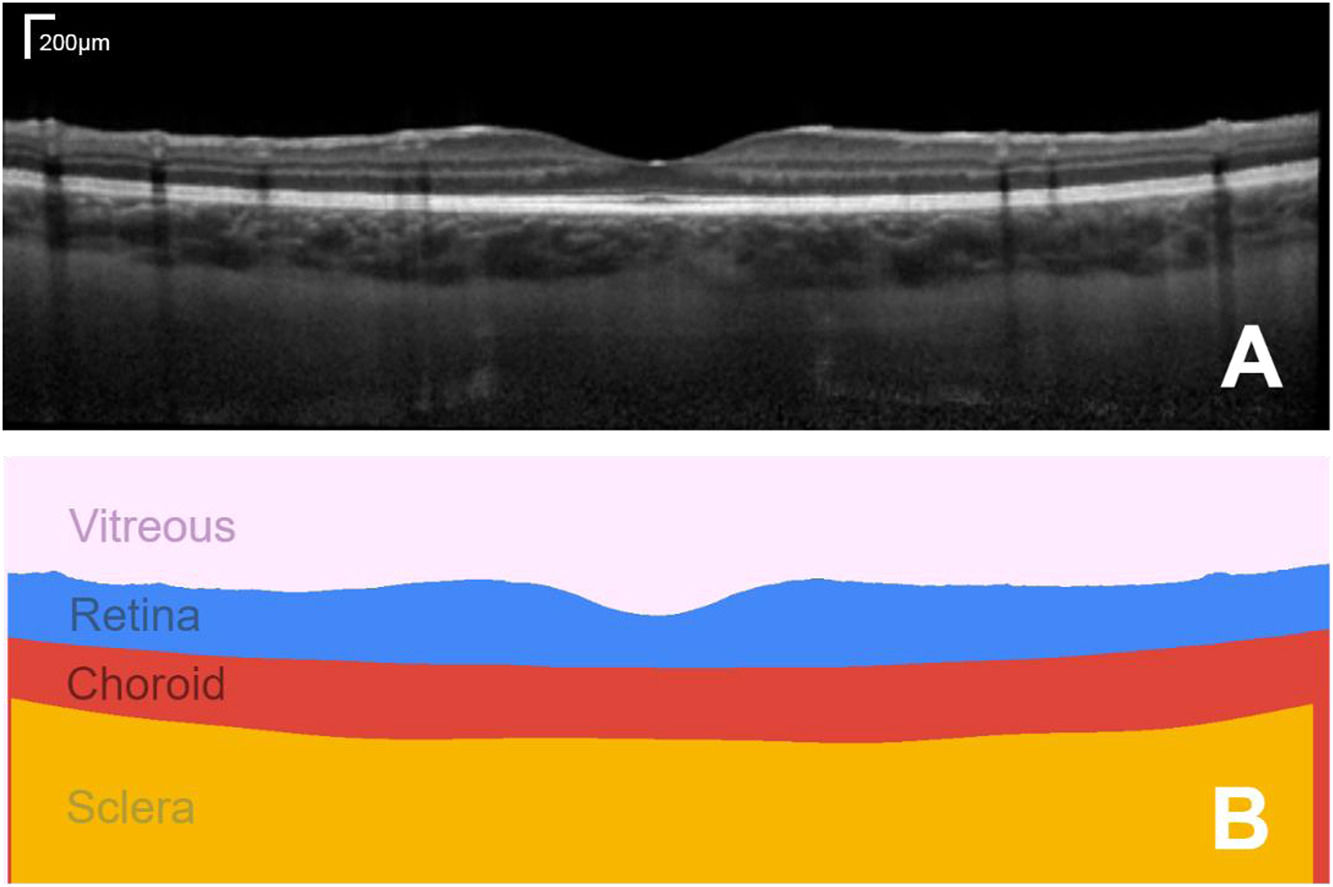
The ability to non-invasively image the eye with optical coherence tomography (OCT) has transformed the fields of optometry and ophthalmology. Quantifying these images and numerically tracking changes (e.g. in tissue morphology) helps to better drive clinical decision making. OCT is a non-invasive coherent imaging method that is used to capture high-resolution cross-sectional images within optical scattering tissues such as the retina and choroid in the posterior segment of the eye (Fig. 1A). The analysis of such images is widely performed in both research and clinical practice for a range of tasks including measuring retinal and choroidal layer thickness, for monitoring disease progression and for quantifying treatment outcomes (Fig. 1B).
 OCT scan of the posterior segment of the eye of a healthy subject, showing a cross-section of the retinal and choroidal tissue (A) and its corresponding segmented regions of interest, from which quantitative measures of tissue layer thickness can be derived (B). Bar in top right of A shows the scale.")
Example foveal-centred spectral domain (SD) OCT scan of the posterior segment of the eye of a healthy subject, showing a cross-section of the retinal and choroidal tissue (A) and its corresponding segmented regions of interest, from which quantitative measures of tissue layer thickness can be derived (B). Bar in top right of A shows the scale.
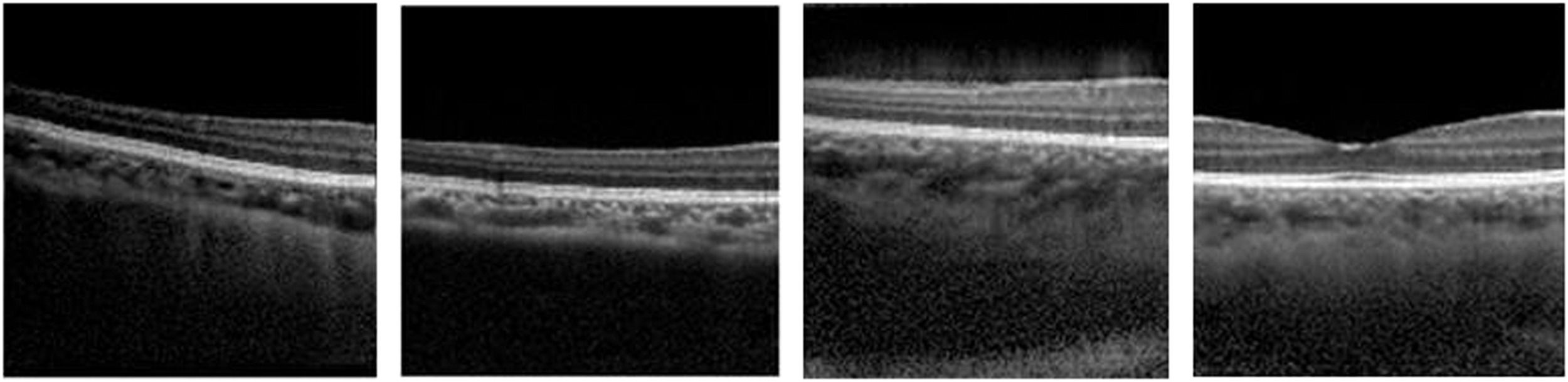
Deep learning methods, a subfield of machine learning, have enhanced image analysis in OCT including for applications such as retinal and choroidal layer segmentation,1-4 optic nerve head segmentation,2 fluid region segmentation,3,5 and pathology detection6-10 and/or grading.11,12 These methods can provide automatic, accurate and efficient solutions compared to traditional manual analysis by human observers. Generative adversarial networks (GANs) are an exciting new group of deep learning methods which have seen significant growth, progress and adoption in many areas in recent years, particularly in the field of medical image analysis where GANs have been applied to a number of ophthalmic imaging modalities including retinal fundus photography, OCT angiography (OCTA) and OCT. This review will focus exclusively on applications to OCT where GANs have demonstrated the ability to “generate” OCT images that are difficult to discern from real OCT images, even for experienced clinicians.13 For instance, Fig. 2 provides examples of four OCT images, three of which are generated by a GAN and one of which is a real OCT image (we encourage the reader to discern which it is). Given the high level of image quality, these GAN images may be used to train clinicians and even used as additional data for enhancing image analysis algorithms.
.")
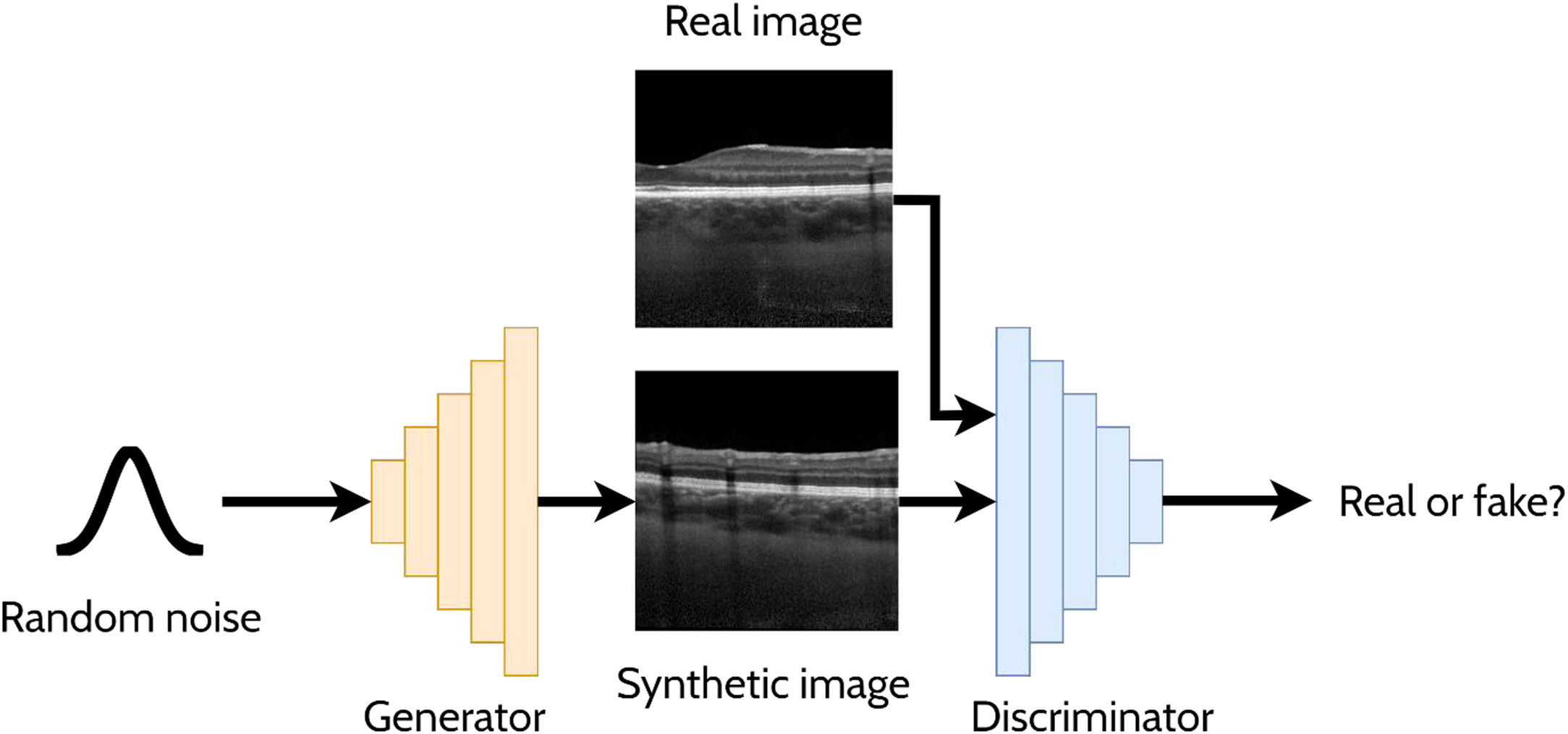
A GAN is a powerful and versatile deep learning method, particularly as a generative method for image synthesis (i.e. image generation) and related applications. The original GAN14 (Fig. 3) consists of two deep neural networks, a generator and a discriminator, competing against each other to improve their performance. Using a random noise vector, also called the latent code, as input, the generator's goal is to synthesise realistic images such that the discriminator cannot distinguish them from the real images. In this context, the images produced by the generator are referred to as the “synthetic” or “fake” images. Through an iterative training process, the generator and discriminator both become stronger, with the generator learning to produce increasingly realistic images to “fool” the discriminator, while the discriminator also improves its ability to distinguish between real and fake images. The original GAN architecture,14 proposed in 2014, has been upgraded over the years to improve its performance, its training convergence and to expand its application capability. A few of the most notable upgrades include that of Radford et al.15 who replaced the multi-layer perceptron (MLP) based architecture with a convolutional neural network (CNN) based one and proposed the deep convolutional GAN (DCGAN), which enabled the GAN to generate higher quality images. Mirza et al.16 extended the idea to the conditional GAN (cGAN) by incorporating an additional auxiliary input, such as a class label (e.g. type of disease in the image), which can be used to condition the input, thus providing control of the generated image (e.g. generate an image exhibiting particular disease characteristics). Expanding on the conditional approach, the discriminator in the auxiliary classifier GAN (ACGAN)17 was given the additional task of classifying each image (e.g. determining whether the image contains pathology A or pathology B). For exploiting both labelled (images with annotations) and unlabelled (images without annotations) data, the semi-supervised GAN18 operates in either supervised mode (classifying image into one of K classes) or unsupervised mode (real or fake), with the GAN discriminator possessing K + 1 outputs (an extra fake class is added). For example, taking the case of OCT disease classification, the GAN may be able to learn useful information (for the classification problem) about the images without these images being explicitly labelled with a disease (unlabelled). This can yield improved performance (more accurate classification) compared to using just labelled images and reduces the need for expert labelled data.
 for generating cross-sectional retinal OCT images. The generator takes a random noise vector as input and produces a synthetic image. The discriminator is required to distinguish between the synthetic (fake) images (created by the generator) and the real images.")
Overview of a generative adversarial network (GAN) for generating cross-sectional retinal OCT images. The generator takes a random noise vector as input and produces a synthetic image. The discriminator is required to distinguish between the synthetic (fake) images (created by the generator) and the real images.
In this paper, a comprehensive review of GAN applications in optical coherence tomography is performed to identify where and how GANs have been used for OCT image analysis tasks, highlighting where possible its clinical application and motivation. Additionally, the gaps in the existing literature are discussed in terms of the potential for future work in the area where GANs may be used further to enhance OCT image analysis. This is a rapidly growing field and this review aims to provide an overview of the current state of development in GAN applications in OCT image analysis, and to stimulate future research within the area.
GAN applicationsGiven their demonstrated benefit for a number of applications in several areas of medical image analysis, GANs have been increasingly adopted for OCT image analysis tasks. Their most obvious and natural application is that of image synthesis (synthetic data generation). Hence, several studies have initially investigated the feasibility of generating realistic OCT images using GANs.13,19-21 However, there are a range of other applications for OCT image analysis that have been explored using GANs. These applications, which are summarised in the following sections, include: anomaly detection, domain translation, super-resolution, image enhancement, de-noising, data augmentation, shadow removal, segmentation, classification, and prediction. Although the main motivation of this work is to summarize and review these GAN applications, the clinical benefit and impact of these applications is also highlighted, where possible.
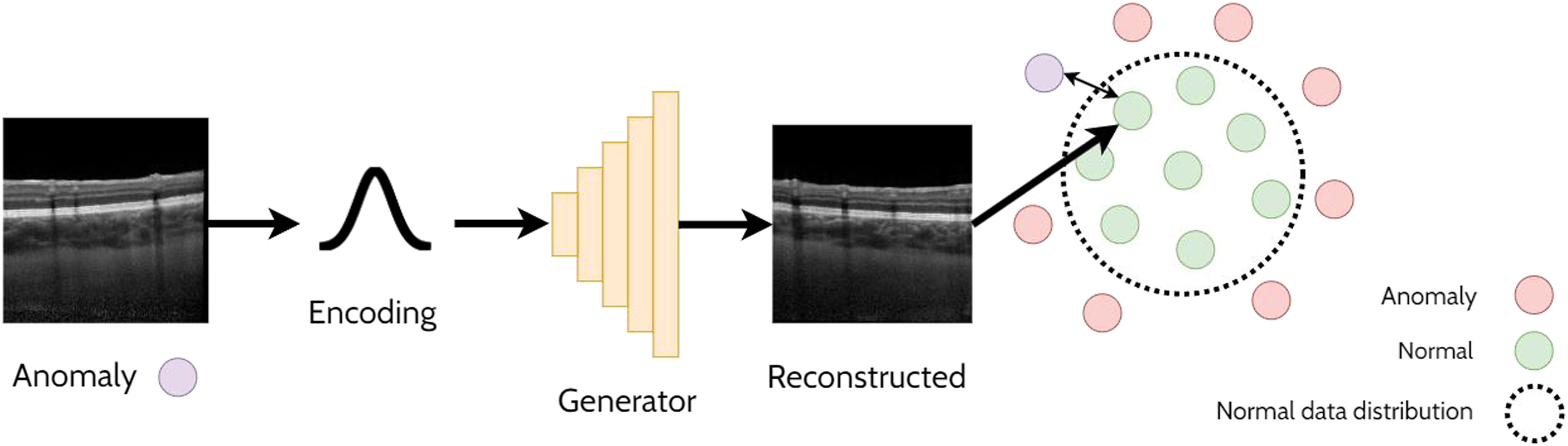
Anomaly detectionAnomaly detection refers to the task of detecting out-of-distribution (anomalous) samples (images) while anomaly localisation refers to the detection of anomalous regions with the samples (i.e. specific regions within images). For example, anomaly detection could involve the detection of OCT images of pathology from those that are healthy, whereas anomaly localisation could involve the localisation of pathology specific features (e.g. subretinal fluid) within these images. One approach for anomaly detection is by using a GAN to learn the data distribution and then using a second step to determine whether a given image belongs to the learnt GAN distribution (non-anomaly) or not (anomaly). This relies on the assumption that the GAN will only be able to generate images from within the learnt distribution and will not be able to reliably reconstruct anomalous samples. A handful of studies have explored anomaly detection and localisation using GANs in retinal OCT images22-27 which will be summarised in the following sections. An illustrative example of using a GAN applied for anomaly detection is depicted in Fig. 4.
AnoGAN
The AnoGAN22 is initially trained to generate patches of normal OCT images. The method then adopts an iterative process to update a randomly initialised latent code to minimise the difference between the corresponding generated (reconstructed) OCT image patch (generated using the latent code) and the original target (real image) OCT image patch. Sufficiently large differences in the reconstructed image compared to the original are used to detect and flag whether the original image is anomalous. In this case, anomalies consisted of images that contained retinal fluid or hyperreflective foci. The specific spatial locations with the largest differences can be used to identify the locations of the anomalies (anomaly localisation). The updated version of this network, the f-AnoGAN23 improves this process by incorporating an additional neural network (an encoder) to map the original target image to a latent code which is then provided as input to the generator. The reconstruction difference between the target image and the generated image can then be used to detect and localize anomalies in the OCT images in a similar way to the AnoGAN. This approach works under the assumption that normal OCT images will be correctly encoded and reconstructed by the GAN whereas out-of-distribution (anomalous) images will not, leading to a higher reconstruction error (difference between original and reconstructed images) as these images do not exist within the normal data distribution that was initially learnt by the GAN.
OtherRather than calculating differences and detecting anomalies on the image level (e.g. AnoGAN), another approach uses a Sparse-GAN24 which instead computes the anomalies with respect to the latent codes to detect lesions within OCT images including those of drusen, diabetic macular oedema (DME) and choroidal neovascularization (CNV). Wang et al.26 used a weakly-supervised (using imprecise annotations) method based on CycleGANs28 and reconstructed the normal anatomical structures from abnormal input images to detect and segment lesions, including drusen, DME and CNV. Zhou et al.27 proposed the P-Net to perform anomaly detection by leveraging the relationship between structure (the regions and layers) and the texture of OCT images. Here, an image reconstruction module is proposed to 1) segment the image and obtain the semantic area mask, 2) encode the semantic area mask and image separately, 3) reconstruct the OCT image based off the two encodings. The difference in the extracted structure of the reconstructed OCT image and the original is used for anomaly detection.
Advantages and disadvantagesCompared to other machine learning-based anomaly detection methods, there are several advantages of GAN-based methods for anomaly detection in OCT. Firstly, these methods require no supervisory signal foregoing the need for any manual labelling compared to other deep learning approaches which may employ supervised, semi-supervised or weakly supervised techniques. Second, these methods are well suited to image data and yield higher accuracy and robustness given the ability of GANs to model complex data distributions and generate highly realistic and diverse images. Third, GAN-based anomaly detection methods require relatively little tuning and manual calibration and scale well with increasing data. However, one common drawback of GAN-based approaches for anomaly detection is the need for significant amounts of training data for the method to perform well. Nonetheless, GANs for anomaly detection have demonstrated significant potential to be useful tools in clinical practice for identifying and highlighting pathological regions within the retinal tissue.
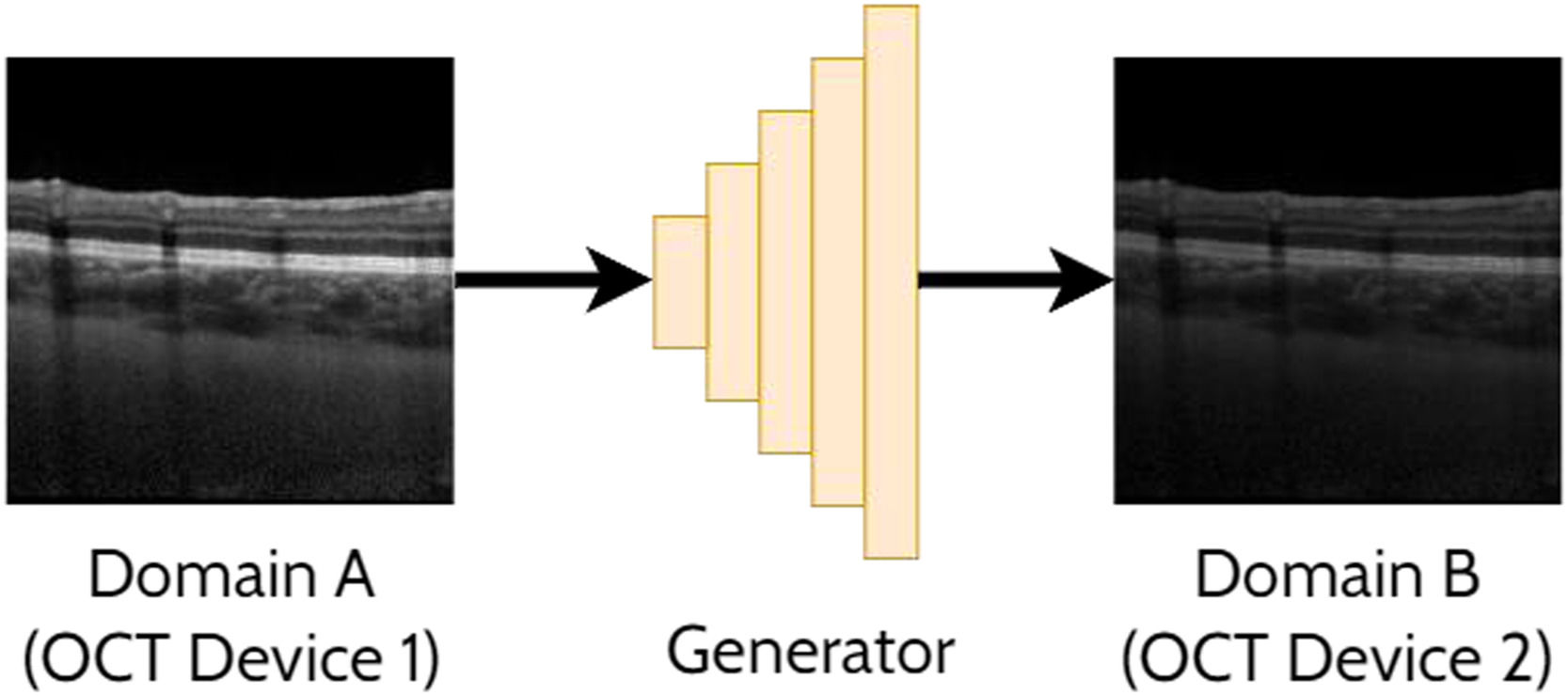
Domain translationDomain translation refers to the idea of taking a sample (image) from one domain and transferring that to its representation in another domain. For instance, this may involve translating an OCT image acquired by one OCT instrument (domain A) to resemble an image acquired by a second OCT instrument (domain B). Similarly, this could involve translating an image acquired using one set of scanning parameters (domain A) to resemble an image acquired using a second set of scanning parameters (domain B). This has potential benefits including the ability to analyse images from multiple domains with an algorithm developed exclusively for one particular domain (e.g. images from a range of OCT instruments could be translated into a single ‘universal’ one for processing purposes). With these methods an important focus is ensuring that the ‘content’ or structure of a given image remains unchanged while just transferring the ‘style’ of the image. This is of particular importance to ensure such that clinically useful and reliable data can be derived. For OCT images, the content can refer to the structure of the tissue (i.e. critical anatomical features such as the position of the retinal layers and pathological regions) while the style can refer to features such as the particular level of speckle noise as well as the contrast between the retinal layers. A range of prior studies have investigated domain translation between two OCT instruments29-38 which will be summarised in the following sections. An example of applying a GAN to domain translation in OCT images is illustrated in Fig. 5.
CycleGAN based
A handful of methods have utilised CycleGAN as the basis of the domain translation approach. To improve retinal fluid segmentation and photoreceptor layer segmentation, Seebock et al.29 and Romo-Bucheli et al.30 used CycleGANs to translate between OCT images of two devices (Zeiss Cirrus to Heidelberg Spectralis images) taking patches of OCT images from a cross-domain dataset consisting of age-related macular degeneration (AMD), retinal vein occlusion (RVO) and DME. In another set of studies, Lazaridis et al.31,32 utilised an ensemble of spatially coherent CycleGANs to convert from time-domain OCT (TD-OCT) (low signal to noise ratio) to spectral domain OCT (SD-OCT) (higher signal to noise ratio), thus improving OCT image quality.
OtherHe et al.33 achieved a similar goal to the aforementioned CycleGAN methods but instead employed two discriminators (one for masks and one for boundaries) to constrain and ensure the correctness of the target OCT image anatomy. Yang et al.34 adopted local and global discriminators and alignment modules for cross-device OCT lesion detection including subretinal fluid (SRF), CNV and retinal pigment epithelium atrophy (RPEA). Wang et al.35 used a domain adaption model to improve classification accuracy for retinopathy detection from cross-domain OCT images by extracting invariant and discriminative characteristics shared by the images from two different OCT instruments (Heidelberg Spectralis and Zeiss Cirrus). Zhang et al.36 ensured that the noise patterns were similar between domains, and used a noise adaptation approach consisting of two discriminators, one to ensure that the noise patterns were similar to the target domain and the other to enforce the content (structure of the tissue and layers) to be preserved in the generated OCT images. Bian et al.37 used adversarial learning (i.e. using a GAN) for unsupervised domain adaptation with two OCT instruments (Heidelberg Spectralis and Optovue) as part of the uncertainty-aware domain alignment method for retinal and choroidal layer segmentation in OCT images. Chai et al.38 incorporated a perceptual loss39 on the output segmentation maps such that the choroidal structure is preserved between different OCT domains in an unsupervised manner.
Advantages and disadvantagesA clear advantage of using GAN-based approaches for domain translation is the high level of realism and quality of the generated images. Additionally, the rules of the transformation are automatically learnt and do not need to be handcrafted or manually specified. There is then less reliance on domain-specific knowledge and understanding of the domains in question which can allow for more accessible and efficient development of these methods. As highlighted above, GANs are also adept at learning the transformation between domains without requiring labelled pairs of images. This is a significant advantage over other methods as it means that these models are more readily trainable and do not require the time-consuming and often tedious collection of additional paired data, which can also be difficult to obtain depending on the application and type of data required. Despite the advantages, one disadvantage of GAN-based approaches for domain translation is the need for large and diverse datasets for training which can be difficult to acquire in certain situations, particularly in the medical domain. This problem is amplified for domain translation in particular, as sufficient data from two domains are required, rather than just one. As discussed, GANs have been applied in numerous studies to translate images from one domain to another such as translating an image from the style of one instrument to another. However, there is no study which has investigated a single model for translating between multiple pairs of instruments which would allow for a more unified and efficient solution.
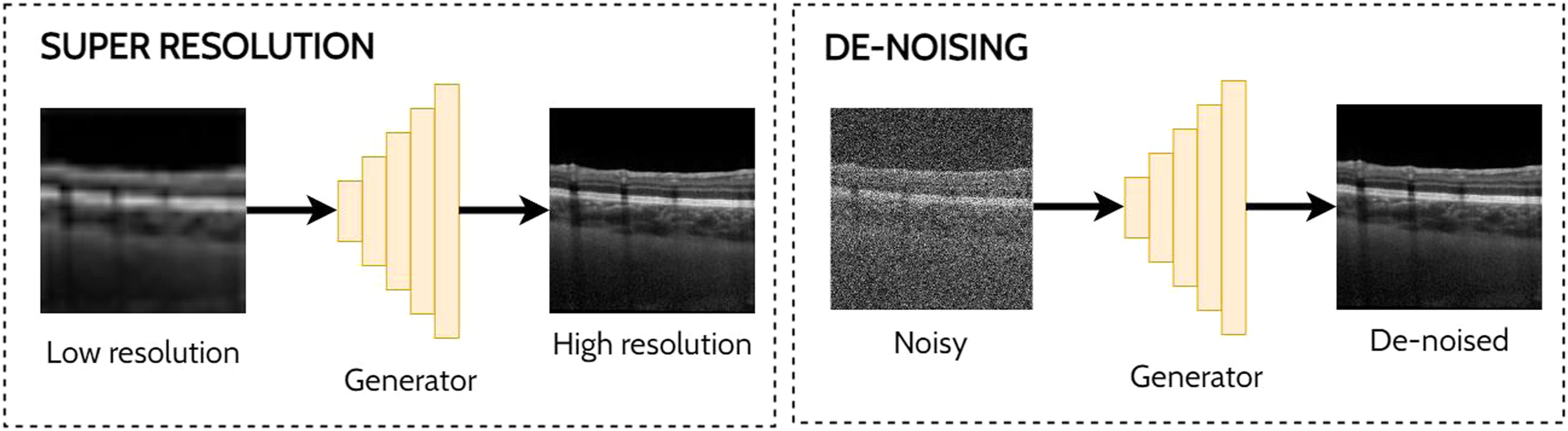
Super-resolution and de-noisingSuper-resolution and de-noising can both be considered as specific examples of domain translation. Super-resolution involves taking a low-resolution image and transforming this to its high-resolution equivalent which may provide additional information or better visualization of the ocular tissue. With the goal of improving the analysis of noisy OCT images, de-noising involves the process of reducing the speckle noise which is an inherent property of coherent imaging techniques such as OCT. One approach for reducing speckle noise is to perform real-time image averaging during scan acquisition with the OCT instrument. However, this requires a prolonged scan acquisition time which is not always feasible, particularly in the cases of poor fixation. Hence the need for post-processing methods such as a GAN to perform this task and enable improved visualisation of the tissue structures in the image which can prove challenging in the presence of high levels of noise. Examples of applying GANs for super-resolution and de-noising in OCT images are depicted in Fig. 6.
Summary and de-noising application (right) in OCT images using GANs.")
There are several existing methods for super-resolution40-46 and de-noising40,47-61 for OCT images. Common trends include the use of a perceptual (content) loss (using a pre-trained network) and/or a structural similarity loss for preserving structural information within the generated OCT images,40,41,45,47,55-59 and the adoption of PatchGAN discriminators (discriminate on the scale of patches of the images rather than the full images).42,43,48,53,54,60 There are several examples of both supervised (i.e. using paired data with both the noisy and averaged image pairs)41,43,49,51,54-56,59 and unsupervised (i.e. using unpaired data with only the noisy images)42,50,52-54 approaches with just a single semi-supervised (using both paired and unpaired data) approach published to date.58 The following sections summarise these studies categorised into supervised and unsupervised methods.
Supervised methodsFor supervised methods, the target (reference) super-resolved or de-noised OCT images are available and explicitly utilised. Huang et al.40 performed simultaneous de-noising and super-resolution of AMD OCT images and proposed the SDSR-OCT method with a network based on the dense deep back-projection network for super-resolution.62 Hao et al.43 used a Pix2Pix GAN to reconstruct high-bit depth OCT scans (12-bit) from low ones (3–8 bit). The OCT-GAN47 aimed to remove noise from optic nerve head images and uses three pre-trained networks to preserve the content and style of the OCT images, as well as to avoid blurring. Ma et al.48 used a supervised image-to-image translation approach for de-noising OCT images of patients with central serous chorioretinopathy (CSC) and pathological myopia (PM) and combined an edge loss function to increase sensitivity to and better preserve edge based details (i.e. the retinal layer boundaries). Chen et al.49 proposed the DN-GAN for SD-OCT de-noising in optic nerve head images (Heidelberg Spectralis) using an image-to-image translation approach (convert high noise to low noise) which used two reconstruction losses, one in the spatial domain (as standard) and the other in the frequency domain. For both normal and pathological eyes, Guo et al.57 also utilised CycleGAN for unpaired SD-OCT (Heidelberg Spectralis) de-noising proposing the structure-aware noise reduction GAN (SNR-GAN) utilising a structure-aware loss (SSIM) to aid in preserving the different structures within the OCT images during the de-noising process. Viedma et al.,61 utilised CycleGANs for de-noising healthy SD-OCT images with the goal of improving semantic segmentation performance of the retinal layers. The SiameseGAN55 uses an additional siamese twin network taking matching (identical ground truth images) and non-matching (ground truth and generated images) pairs to improve GAN training and produce higher-quality de-noised SD-OCT (Bioptigen) images of both normal and AMD patients.
Unsupervised methodsFor unsupervised methods, the target OCT scans (i.e. de-noised or super-resolved image) are not available for training while only some are available for semi-supervised methods. Das et al.42 used CycleGANs for unsupervised OCT super-resolution to improve AMD diagnosis. For both normal and AMD patients, Guo et al.50 performed unsupervised de-noising of SD-OCT (Bioptigen) image patches without reference clean images, instead assuming the speckle noise distribution using ‘background’ regions from the noisy OCT images. To de-noise retinal OCT (Heidelberg Spectralis) images of various diseases (and different stages of disease), Manakov et al.52 used a modified CycleGAN (HDCycleGAN) in an unsupervised fashion with just a single discriminator such that the discriminator can focus on the differences between the noisy and the averaged images. Using a CycleGAN approach with two separate encoders, Huang et al.53,54 proposed that noisy SD-OCT images (from both normal and AMD patients) can be represented in both a content space and a noise space while the clean images are represented solely in the content space (no noise). Wang et al.58 performed semi-supervised de-noising of swept-source OCT (SS-OCT) images (acquired using Topcon Atlantis) using a capsule network63 based conditional GAN again employing a structural similarity loss to preserve important structural information (i.e. the retinal layers). Here, the model is initially trained on the paired images (supervised). Afterwards, semi-supervised training is performed with both supervised (reconstruction, structural similarity, and adversarial losses) and unsupervised (adversarial loss only) modes which exploits the use of unpaired data to improve de-noising performance, therefore requiring less data to be acquired in the first place to train the model.
Advantages and disadvantagesThere is extensive work for image enhancement techniques of OCT images using GANs, predominantly for de-noising and super-resolution. One particular advantage of GANs for image enhancement and de-noising is that these can be used without paired samples. For instance, it may be difficult to acquire paired low-resolution and high-resolution images that are aligned precisely at the same location within the tissue. Another advantage of using GANs compared to other methods in these cases is the ability to synthesise images that are highly realistic. This is a particular challenge with other image enhancement methods in general which often produce images which contain artifacts or overly blurred features. Indeed, retaining the anatomical structure and details within the images is of utmost importance such that clinically derived metrics are unaffected by the enhancement process. However, a particular ongoing challenge in developing image enhancement methods is determining the best metrics to use to evaluate the quality of the enhanced images. Despite their advantages, one particular disadvantage of GANs is the need for significant amounts of data to train the models well. Without this, GANs can fail to generalise well to new, unseen data. This can lead to erroneous images or even the case where the translated, enhanced images can resemble those in the training set, rather than resembling the input image of interest.
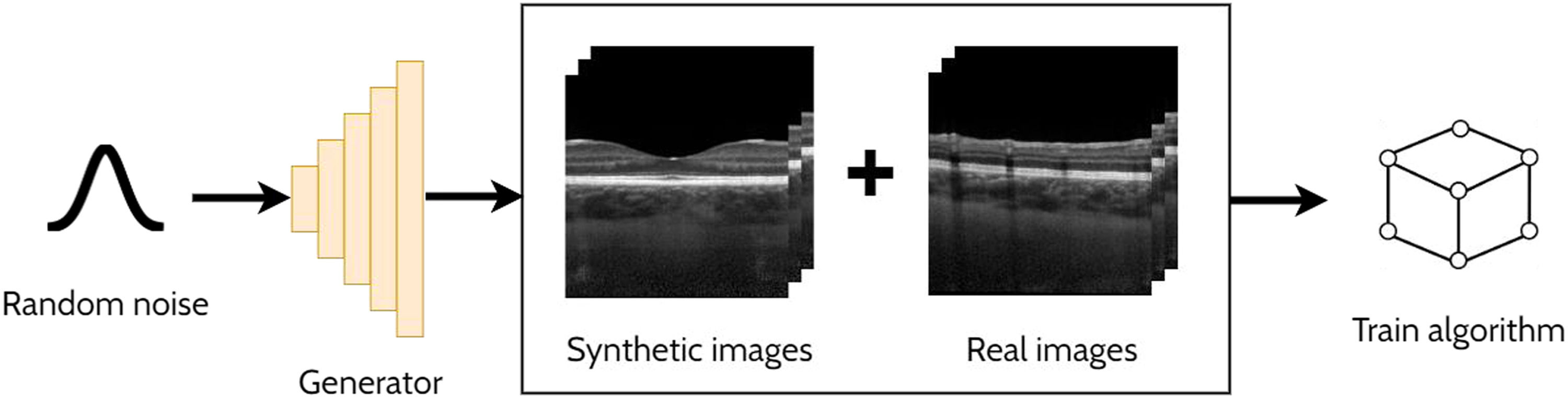
Data augmentationDeep learning methods generally require sufficiently large and diverse annotated datasets for ample performance. However, this is often difficult, particularly in the medical domain, due to privacy concerns and the issues posed by the significant time and cost to collect and annotate large volumes of data. One method to address this is to employ data augmentation to artificially enhance the dataset using simple image transformations such as rotations and contrast adjustments. Data augmentation is another application of GANs which involves combining the synthetic data generated by a GAN with the original real training data. In general, this increase in data can help the training and generalization of the model. The additional benefit here is that the GAN can synthesise new samples from within the learnt distribution which are beneficial for the learning task of interest. For instance, if we consider the task of OCT retinal layer segmentation with a low number of images to train the model, a GAN can be used to effectively increase the number of training images (i.e. generate new ‘synthetic’ samples). Hence, the combination of the new synthetic training data and the real training data can potentially improve the performance of a particular task compared to just using real training data alone. GAN-based data augmentation has been used to enhance OCT retinal segmentation,64-68 and classification69,70 methods which are summarised in the following sections. Fig. 7 provides an illustrative example of an OCT data augmentation application using GANs.
Segmentation
For segmentation, Kugelman et al.64,66 performed data augmentation using conditional GANs to enhance the training set of SD-OCT (Heidelberg Spectralis) patches for retinal and choroidal layer segmentation in images of healthy eyes. Mahapatra et al.65 performed data augmentation for retinal OCT segmentation of pathological regions including intraretinal fluid (IRF), SRF, and pigment epithelial detachment (PED) in images of patients presenting with AMD and RVO. SD-OCT scans were acquired from OCT instruments from three different vendors: Cirrus HD-OCT, Spectralis and Topcon. Here, they adopted a geometry-aware GAN (GeoGAN) to generate a new image and segmentation mask by jointly encoding an image and mask and performing hierarchical uncertainty sampling within the generator.
ClassificationFor data augmentation in classification, Chen et al.69 used conditional GANs to generate diverse images of different modalities including for OCT images of normal patients and those with retinal diseases (CNV, DME, drusen) to be used for retinal disease detection. Diversity is introduced by inserting noise to the middle layers of the generator to introduce variations to the images. Given the unbalanced nature of the data, Yoo et al.70 used a CycleGAN to generate pathological OCT images (from healthy ones) which were then used to augment data to train a classifier of rare retinal diseases, such as CSC, macular telangiectasia, Stargardt disease, retinitis pigmentosa, and macular hole as well as more prevalent retinal diseases such as DME, drusen and CNV. GANs were trained individually for each of the diseases.
Advantages and disadvantagesThere are several advantages of GANs for synthesising images for data augmentation including the high level of quality and diversity possible with state-of-the-art GAN methods. Additionally, GANs automatically learn the data distribution in question, removing the need for manually specifying the rules for augmenting the images and can often be easily combined with standard data augmentation techniques to improve performance. However, one significant limitation of GANs for data augmentation is that they become restricted to only generate images that are similar to the training set which can limit their effectiveness depending on the application and dataset. Indeed, images that do not resemble those within the training set will be flagged as fake by the discriminator and the generator will therefore not tend to produce those. Overall, there are just a few studies, however given these results highlight a real potential for this application in OCT, further studies are warranted in the future. Utilising synthetic data for data augmentation has demonstrated a use for improving the accuracy of classification and segmentation methods in OCT particularly in cases where large and diverse labelled datasets are difficult to obtain.
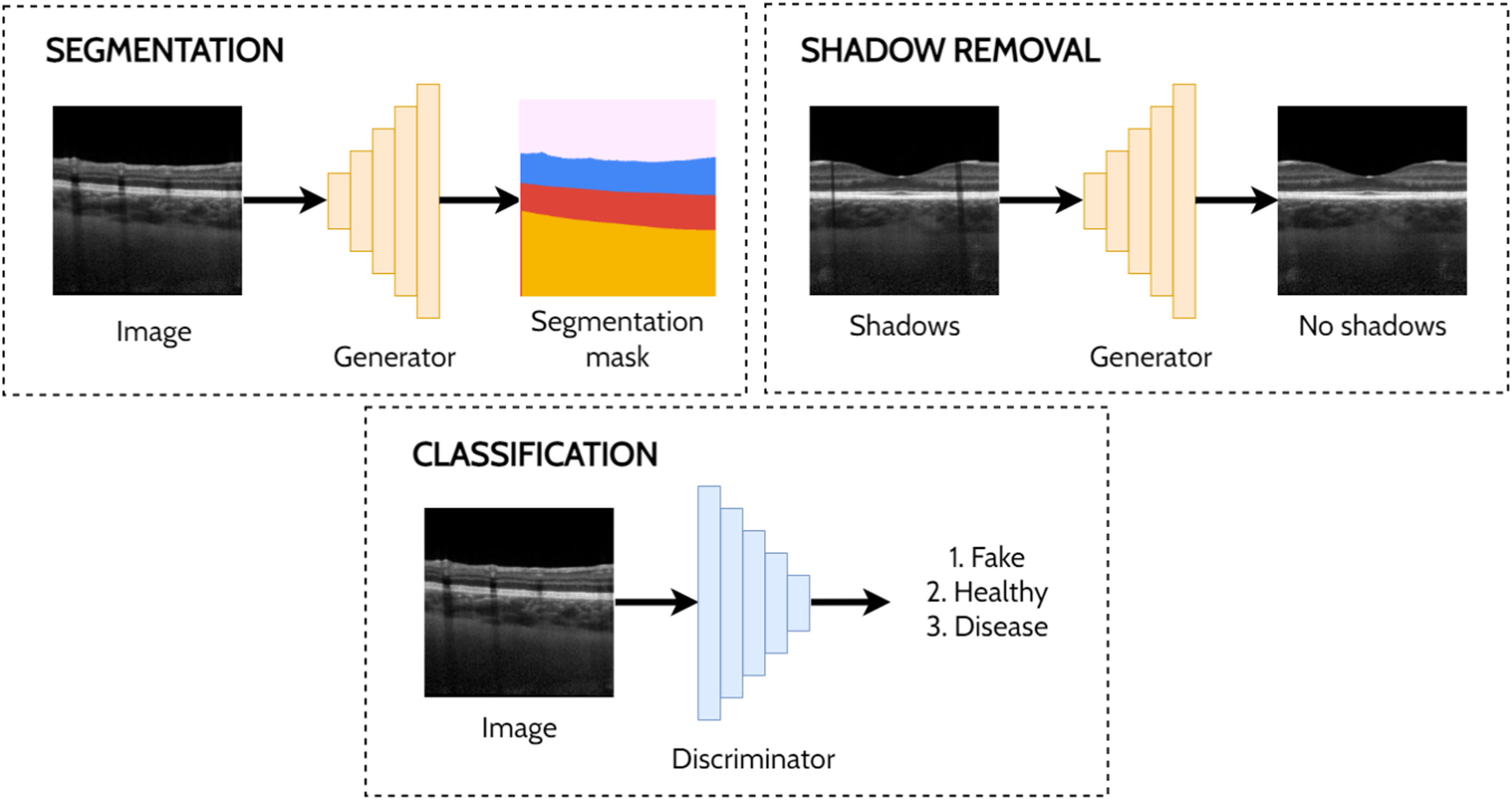
Other applicationsThere are several other applications of GANs to OCT image analysis including a handful of studies investigating shadow removal,47,71 segmentation,72-74 classification75 and prediction.76 De-shadowing OCT images involves the removal of shadow artifacts caused by the obstruction and optical scattering by the retinal blood vessels. Such shadows can be problematic for image analysis due to the difficulty in visualising the structure of the tissue in the shadowed regions. DeshadowGAN,71 and OCT-GAN47 both adopt supervised approaches employing shadow removal and shadow detection networks. The DeshadowGAN shadow detection network combines a content loss (to ensure non-shadow regions of the images are not altered), style loss (to ensure image texture remained similar), total variation loss (to avoid checkerboard artifacts) and shadow loss (based on the shadow detector network, to ensure shadows had been removed). Ouyang et al.72 used conditional GANs to perform pre-segmentation of anterior OCT images (both corneal and limbal images) to remove speckle noise and specular artifacts above the shallowest interface. Liu et al.73 used an image-to-image translation approach with a GAN to perform semi-supervised segmentation of retinal layers and fluid regions in OCT images of DME. Here, they leverage the unlabelled data to improve performance by using a fully-convolutional discriminator with a confidence map output to highlight trustworthy segmented regions in the unannotated images which are then used to guide the training. Das et al.75 applied a semi-supervised approach for classification of normal OCT images and those exhibiting ocular pathologies (AMD, DME), simultaneously training for classification (labelled images) and in an adversarial manner (unlabelled images). For prediction, Lee et al.76 used GANs to predict OCT scans post-treatment for age related macular degeneration. Fig. 8 provides illustrative examples of segmentation, shadow removal and classification for OCT images using GANs.
Conclusions and future work
This review has covered the extensive use of GANs for applications in OCT image analysis including for anomaly detection, domain translation, super-resolution, de-noising, data augmentation, segmentation, classification and prediction. In many cases, GANs provide an improved approach compared to other deep learning and traditional algorithms and techniques. Indeed, for many of these applications GANs are state-of-the-art in terms of their accuracy (e.g. anomaly detection) and the quality of the output images (e.g. de-noising). The innate ability of GAN's to model and learn complex data distributions is particularly suited to image-based tasks, hence their state-of-the-art performance and increasing use in medical image analysis including OCT. In OCT, the power of GANs is also highlighted by their demonstrated ability to synthesise realistic images that can fool even experienced clinicians.13Fig. 2 illustrated the difficulty in discerning real OCT scans from fake ones generated by a GAN (in this case only the second leftmost image is in fact real).
While some applications have received more attention than others there are also some notable gaps. Despite the studies in domain translation with two OCT instruments, no studies have investigated this application in the multi-domain setting with more than two OCT instruments. A single model capable of translating images between a range of different OCT instruments would allow for more unified and streamlined approaches to OCT image analysis and would allow algorithms developed using particular imaging modalities to be compatible with other modalities. There is also limited work performing adversarial segmentation of posterior OCT images (either supervised or semi-supervised). In the supervised setting there is the potential for improving the segmentation accuracy of existing approaches by incorporating a GAN loss while in the semi-supervised setting unlabelled data can be exploited to improve performance which is of significant interest in medical image analysis where labelling large datasets can be costly, time consuming or infeasible. There is also very limited work for patch-based data augmentation for OCT segmentation with only a single set of studies on healthy data and similarly limited studies investigating data augmentation using GANs for existing OCT semantic segmentation methods. Fast and accurate layer segmentation, especially in a low-data setting, is crucial in both research and clinical practice.
Although this review has focused on OCT in a comprehensive manner, there are similar GAN applications in other areas of ophthalmic image analysis including for retinal fundus photography (RF)77-83 and OCT angiography (OCTA) .84 The area of GANs is rapidly evolving and this review aims to provide a window into their wide and increasing level of application to optical coherence tomography. It is hoped that this review will aid future research direction and projects in this research space. GANs have shown promise in various OCT image analysis applications and are likely to further contribute to this field in the future, particularly considering the rapid advances that have been observed in the short time since GANs have been introduced. As a consequence, research and clinical decision making should positively benefit from these automatic and reliable image analysis methods.





